¿Deberíamos usar Chat GPT en el Sur Global?
Sobre la retroalimentación de los sesgos implícitos en la IA generativa en las identidades del Sur Global


Por Mauricio Franco
Se ha hecho mucha investigación sobre los problemas técnicos, éticos y sistémicos que posan las tecnologías de “inteligencia artificial generativa”, sin embargo, esa discusión no se ha tratado a profundidad desde la perspectiva de la creación en el sur global y las repercusiones que, el uso acrítico de estas tecnologías puede tener sobre nuestras comunidades y nuestra propia identidad. En el ensayo propondré que existe la posibilidad de un desarraigo identitario, propiciado por la pátina de objetividad que ofrece una tecnología generativa; se explicará, de forma general y simplificada el funcionamiento de estas tecnologías y se revisarán las ideologías implícitas en los lugares de su origen.
Desde que se comienzan a usar públicamente los primeros modelos de creación de imágenes y texto con la llamada inteligencia artificial, se ha visto interés, sobre todo por líderes de equipos de marketing digital, de utilizarlas en producción publicitaria y páginas web, como una forma de encontrar exactamente lo que se necesita para una pieza, en vez de usar imágenes de stock que encajen sólo “parcialmente”. Debido al paso acelerado de los modelos de agencia no hay un espacio donde se puedan tratar las complejidades éticas de estas nuevas herramientas.
Sin embargo, entender los efectos y mecanismos de la ai generativa es necesario para poder posicionarse como productor y receptor de sus resultados, así como la adopción, transformación o abandono de estas herramientas de ahora en adelante.
1. Cómo se generan imágenes por inteligencia artificial:
El área de estudios de la inteligencia artificial está separada en 3 grandes categorías (Luger, George; Stubblefield, William, 2004.): Razonamiento, Búsqueda y Procesamiento de lenguaje Natural. Para explicar cada una de ellas usaremos ejemplos correspondientes a cada una:
● Cuando buscas una ruta en una aplicación de mapas, el tipo de procesamiento de datos que esta debe hacer es de razonamiento: tiene que evaluar las rutas posibles entre el punto de origen y el punto de destino y tomar una decisión sobre cuál es la ruta más eficiente.
● Cuando buscas información sobre un lugar en un motor de búsqueda o en una enciclopedia digital, éstos deben presentar, no solo las cosas que coincidan con el lenguaje que usaste, sino con temas y frases asociadas para presentarte el mejor resultado, analizando otras variables como tráfico a esos sitios etc.
● Cuando necesitas transcribir un audio, corregir ortografía y gramática, o cualquier otra cosa de ese estilo, estamos hablando de Procesamiento de lenguaje natural.
La explosión de interés en inteligencia artificial sucede en esta última parte, la capacidad de procesar y extrudir[1] correctamente texto coherente con una dirección o “Prompt”.
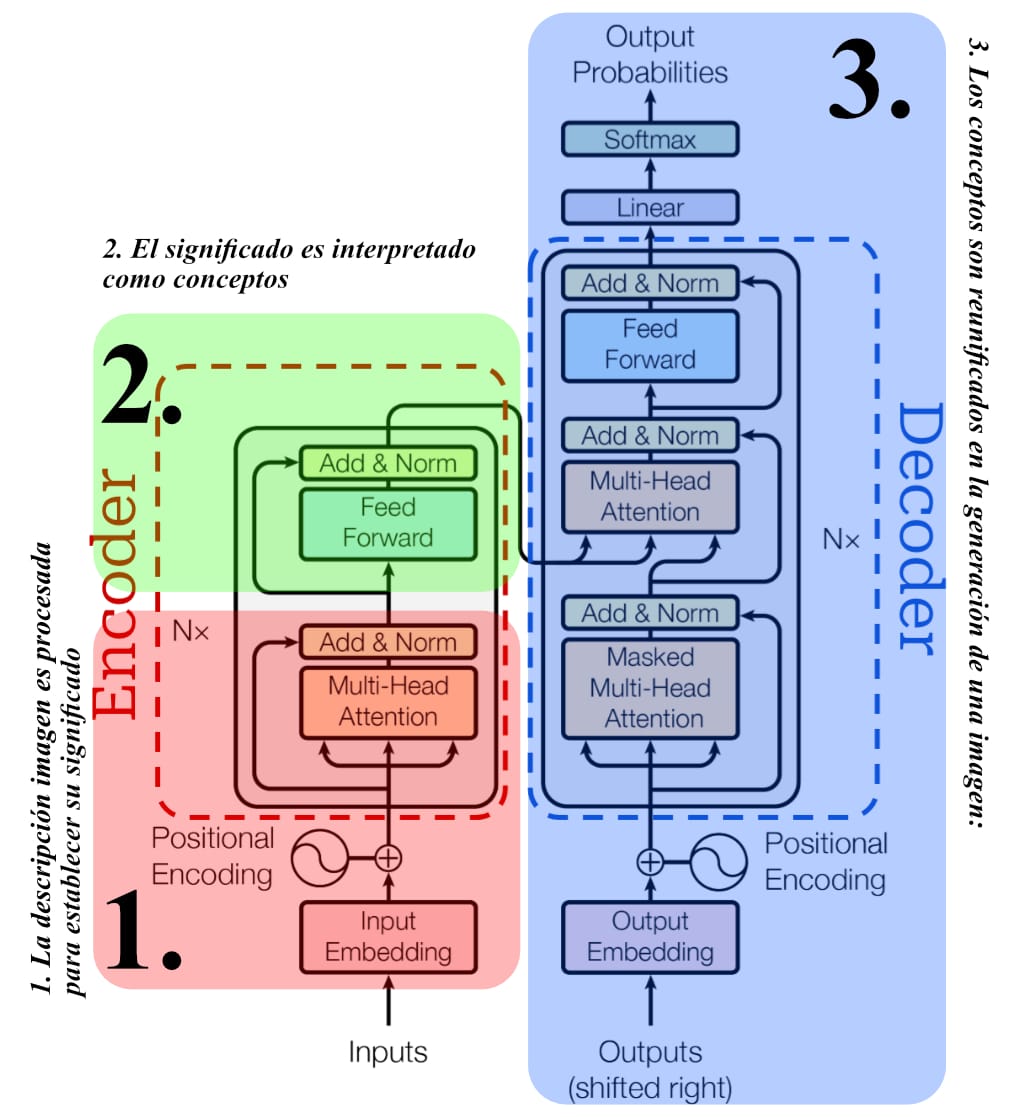
Para generar una imagen a partir de un texto con lo que llamamos IA, pasan varias cosas a partir de la imagen que describes: 1. El prompt es procesado para establecer su significado, 2. Ese significado es interpretado en conceptos; 3. Esos conceptos son unificados de nuevo en la generación de una imagen.
Cada uno de estos pasos es bastante complejo a nivel técnico, pero recorreremos cada uno.
- La descripción de la imagen es procesada para establecer su significado: Para que esto suceda se utiliza un GPT o transformador pre-entrenado general. Este es un programa de computadora que toma el texto y lo separa en pequeñas porciones de caracteres, también llamados “tokens”.
- El significado es interpretado como conceptos: Estos tokens son buscados en una base de datos y se relacionan con conceptos asociados, a este proceso se le llama normalización. Los conceptos son separados por sus funciones: A) Son las partes de la forma. B) Son las indicaciones sobre el tema C) Son los requerimientos que deben estar presentes.
- Los conceptos son reunificados en la generación de una imagen: Habiendo interpretado el significado de la descripción, el texto es decodificado y transformado en una imagen tomando, de bases de datos, las imágenes con clasificaciones que corresponden a los mismos conceptos y, a través de distintos modelos de estimación de imágenes como la auto-regresión, modelos de difusión, redes adversariales o flujos de normalización[2] se ordenan en clasificaciones por promedios arrojando así las imágenes correspondientes.
Para este ensayo, nos vamos a concentrar precisamente en esas clasificaciones, de las que jalan los distintos modelos para clasificar y luego extruir contenido:
Dado que las clasificaciones son el medio para la identificación y estandarización de las imágenes es relevante centrar la atención en la tipología de clasificaciones que dispone el proceso de extrudir el contenido.
2. Datasets
Un Set de Datos es una base de datos con información dentro, o sea, es una compilación de información con distintas anotaciones de cada una de las entradas, de manera que si tienes una palabra como “crear” ésta va a tener, además, una serie de clasificadores como “verbo”, pero también “creatividad” “fabricación” y cosas más conceptuales. De la misma manera, cuando se clasifican Datasets de fotografías se ven algo así:

Como nos podremos imaginar, esas clasificaciones son hechas desde una posición y/o experiencia que inevitablemente las sesga, a pesar de ser percibidas como “una reflexión natural del mundo, en vez de una reflexión construida y situada de una visión particular del mundo” (Scheuerman, Hanna & Denton, 2021). Simplificando: la manera en que los autores de estas clasificaciones, que son algo así como la materia primogénita de las imágenes generadas por “inteligencia artificial”, deciden nombrar y elegir qué clasificación va y cuál no va, así como el término y su definición, además de quién es la mano de obra que trabaja con tales clasificaciones, moldeando así la forma en que esa imagen es vista y regurgitada por los modelos de inteligencia artificial. De alguna manera prueba la noción foucaultiana de que el conocimiento es una práctica imbuida de poder discursivo.
De la misma manera en que la ciencia lo hace más ampliamente, los datos están imbuidos de valores específicos: la forma como son recolectados, el tipo de datos recolectados y cómo son analizados reflejan ideologías implícitas y latentes.
Sin embargo, estas ideologías no están tan ocultas como se podría asumir.
“En una examinación de las categorías de “personas” dentro de ImageNet - derivado de la jerarquía WordNet- Crawford y Paglen encontraron la inclusión de términos misóginos , insultos raciales y etiquetas ofensivas de otros tipos. Prabhu y Birhane extendieron este análisis a otros datasets que derivaron su estructura categórica de WordNet, y encontró que el dataset TinyImages también contenía insultos y otras etiquetas ofensivas” (Scheuerman, Hanna & Denton, 2021).
3. Las Ideologías Latentes
En 2024 Timnit Gebru y Émile P. Torres hacen un recuento histórico de los orígenes y aspiraciones Utópicas y Eugenistas del desarrollo actual de Inteligencia artificial, allí acuñan el término de TESCREAL, que corresponde a Transhumanismo, Extropianismo, Singularismo (tecnológico), Cosmismo (Moderno), Racionalismo, Altruismo Efectivo (por sus siglas en inglés), y Largo-Tiempismo. Durante su revisión rastrean cómo, desde sus inicios, hay algunas concepciones que no se conforman con la ciencia contemporánea, sino son anacrónicas al remitirse a la ciencia racial norteamericana de principios del siglo pasado.
“Las mismas actitudes discriminatorias que animaron a la primera ola de eugenistas permean la literatura y comunidad TESCREAL. Por ejemplo, el Listserv -Lista de correos internos- contiene numerosos ejemplos de citas alarmantes por figuras notables en el movimiento TESCREAL. In 1996, Bostrom argumenta que “los negros son más estúpidos que los blancos” lamentando que no podía decir esto en público sin ser vilificado como un racista, y luego mencionando el N-word3 (Torres 2023a). En una “disculpa” subsecuente por el mensaje de correo, lamentó el uso del N-word, pero no retiró sus alegaciones de que los blancos sean “más inteligentes” (Torres 2023a). También, en 1996, Yudkowsky expresó preocupaciones sobre la superinteligencia, escribiendo: “Robots Superinteligentes=Arios, Humanos=Judíos, la única cosa que previene esto son robots suficientemente inteligentes”. Otros muestran su preocupación argumentando: “dado que nosotros, como transhumanos, estamos buscando obtener el siguiente nivel de la evolución humana, corremos serios riesgos de que nuestras ideas y programas sean marcados por los medios populares como neo-eugenesia, racistas, neonazis, etc.”. De hecho, figuras líderes en la comunidad TESCREAL han citado positivamente, o expresado apoyo por el trabajo de Charles Murray, conocido por su racismo científico y mostraron preocupación sobre presiones “disgenéticas” (antónimo de “eugénicas”) (Torres, 2023a). Bostrom mismo identifica “presiones disgenéticas” como un posible riesgo existencial en su artículo de 2002, junto con la guerra nuclear y un golpe por super inteligencias, en él escribió: “Actualmente parece haber una correlación negativa en algunos lugares entre logros intelectuales y fertilidad. Si tal selección fuera a operar durante un periodo largo de tiempo, podríamos evolucionar en una especie menos cerebral, pero más fértil homo philo progenitus, es decir: amante de muchas crías,” (Bostrom 2002). Más recientemente, Yudkowsky trinó sobre cómo el coeficiente intelectual estaba disminuyendo aparentemente en Noruega, aunque agregó que “el efecto aparece al interior de familias, por lo tanto no se debe a la inmigración o reproducción disgénica” – es decir, extranjeros menos inteligentes migrando a Noruega o individuos con “Inteligencia” más baja teniendo más hijos”
(Gebru, Torres, 2024)
Este tipo de hallazgos sugieren un sesgo en las comunidades populares entre los desarrolladores de software del norte global (Bostrom, hasta 2024 lideraba el Future of Humanity Institute en Oxford)
quienes replican los mitos raciales pseudocientíficos y anacrónicos, que se encuentran, como hemos mencionado, latentes en la taxonomía que rige la generación de imágenes.
El resultado de esto, en la aplicación de estas imágenes en las regiones de sur del mundo, es el refuerzo de estigmas y estereotipos sobre sus habitantes, aumentado además, por la pátina de objetividad que da la interfaz tecnológica que media estas interacciones. Ya hemos visto en el sur leyes redactadas con ChatGPT (Ley contra el abuso infantil en Colombia 2023) y argumentos redactados con las mismas en los cuales los casos referentes eran ficticios. Pero las imágenes son más incipientes y convincentes, debido a que lo visual, dada su integralidad que conjuga lo intelectual y lo emocional, suele ser más llamativo y persuasivo, cosa de la que se tiene consciencia desde la época antigua en que se desarrolla la retórica.
4. Consideraciones Finales
Mientras surge el interés en el sur global por el uso de imágenes generadas por “Inteligencia Artificial” para usos comerciales es importante lo que significa el uso de estas mismas, cuyas taxonomías e ideologías de desarrollo están marcadas por racismos implícitos y explícitos, para las poblaciones a las que serán expuestas. A nivel personal considero que es posible que refuerce nociones de inferioridad, cree expectativas falsas sobre el mundo y altere las concepciones que estas personas tienen sobre sus culturas y naciones, reemplazandolas por las percepciones de personas que ignoran su historia y clasificadas por personas desinteresadas por hacer justicia a las mismas, mientras reproducen estereotipos dañinos al respecto.
DalBem y Bustamante (2024) recolectaron 2,057 imágenes generadas por Inteligencia Artificial y encontraron claros ejemplos de esto, como que estas privilegiaban personas blancas como protagonistas, entremezclan países y culturas y les homogeniza con nociones estereotípicas como calles con construcciones coloniales, autos antiguos, etc.

Una forma de resistir esto es promoviendo políticas de soberanía de datos que permita a distintos países y comunidades establecer los usos de sus identidades e imágenes de forma consciente y consentida y estimular y exigir la creación de datasets creados y clasificados por personas situadas en perspectivas del sur.
Usamos la analogía de extrudir, porque sentimos que es mucho más apropiada que hablar de “generación” dado que la forma de producción de las herramientas es más cercana a la de un molino para embutidos, donde tomas los datos, son alimentados al molino, que los muele y mezcla para extrdirlos por su boquilla en una nueva forma. ↩︎
Todo esto se refiere a métodos de visualización, en los que no detallaremos. ↩︎
Referencias
- Scheuerman Morgan K., Hanna A, & Emily Denton. (2021). Do Datasets Have Politics? Disciplinary Values in Computer Vision Dataset Development. Proc. ACM Hum.-Comput. Interact. 5, CSCW2, Article 317 (October 2021), 1-37. https://doi.org/10.1145/3476058
- Gebru, T., & Torres, Émile P. (2024). The TESCREAL bundle: Eugenics and the promise of utopia through artificial general intelligence. First Monday, 29(4). https://doi.org/10.5210/fm.v29i4.13636
- DalBem S. & Bustamante C. (Noviembre de 2024). Data Colonialism and Generative AI: An analysis on how large language models reinforce bias and stereotypes University of Texas, Texas, Estados Unidos.
- Luger, George; Stubblefield, William. (2004). Artificial Intelligence: Structures and Strategies for Complex Problem Solving (5th ed.). Benjamin/Cummings. ISBN 978-0-8053-4780-7.
- Cameron R. Wolfe, Ph.D. (31 de Marzo de 2025) Vision Large Language Models. Deep (Learning) Focus) . https://cameronrwolfe.substack.com/p/vision-llms
Glosario:
- LLM (Large Language Model o Modelo Grande de Lenguaje) es el modelo de generación más común cuando hablamos de aplicaciones comerciales de inteligencia artificial. Consiste en el procesamiento estadístico de una gran base de datos de texto para predecir, con base en parámetros dados en un ingreso (o Prompt) un texto de egreso satisfactorio a partir de Tokens.
- GPT (General Pre-Trained Transformer o Transformador Pre Entrenado General): Es una forma de entrenar el modelo para disminuir el tiempo de procesamiento
- Token: Un token es una unidad de análisis en un LLM, corresponde a un número de caracteres convertido a números, cuando un LLM extruye texto está analizando el token que ha extruído anteriormente para plantear el siguiente.
- Extrusión de texto/imágenes: Hablamos de extrusión de texto porque pensamos que es una metáfora más cercana a la realidad que la de “generación de texto”: Los LLMs funcionan como un molino para hacer chorizos, en un lado entran textos hechos por personas (principalmente, en este momento) y estos son molidos, colapsados, homogeneizados para ser extruidos por el otro lado.
- Dataset: una colección de datos recopilados en una o más bases de datos, clasificado según variables definidas.

Sobre el autor
Mauricio Franco es diseñador gráfico, diseñador de producto y maestrando de metodologías y experimentaciones de diseño. Sus intereses están en la tecnología, las visiones de futuro y las ideologías que les alimentan
Conecta con Mauricio


